Troubleshooting – Indexing database
An indexing database is a specialized database designed to efficiently search and analyze large volumes of unstructured or semi-structured data.
In the context of DataMiner, if you do not use the recommended Storage as a Service setup but instead choose self-managed storage, you will need an indexing database (OpenSearch or Elasticsearch) alongside a Cassandra-compatible database service to configure a dedicated clustered storage setup.
An indexing database is required for many DataMiner features, including pattern matching, advanced analytics, DataMiner Object Models (DOM), User-Defined APIs, and more.
Tip
For more detailed information about DataMiner storage, see:
Basic concepts
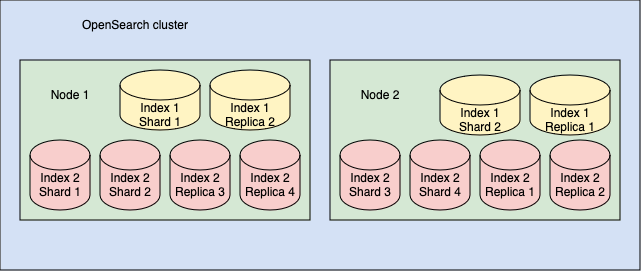
Indexing databases create indexes, data structures that organize and store information to enable fast retrieval. The key concepts of these architectures include:
| Concept | Description |
|---|---|
| Node | A single server within the database cluster that stores data and handles indexing and query operations. |
| Cluster | A collection of nodes that work together as a unified system to store, distribute, and manage data efficiently. |
| Index | A structured dataset used to organize and distribute data by categorizing it for faster querying. This structure can be compared to a table in a relational database. |
| Rollover | The process of creating a new index when the current one reaches a certain size, age, or document count. It ensures data is organized and manageable while automatically updating an alias to point to the new active index for seamless operations. |
| Alias | A logical reference to one or more indexes, enabling seamless index management by abstracting index names. It simplifies query routing, versioning, and updates. For example, in rolling indexes, aliases are crucial for rollovers, pointing to the active index and updating automatically to ensure uninterrupted operations. |
| Shard | A subset or partition of an index, designed to distribute data across multiple servers. This enables parallel processing and improves performance. |
| Replica | A copy of a shard, stored on a different node to ensure data redundancy and increase fault tolerance, providing high availability. |
Tip
For more detailed information about the basic concepts of indexing databases, refer to:
Symptoms of indexing database health issues
When you are using a dedicated clustered storage setup, DataMiner data is stored in an indexing database. In this case, the following symptoms may indicate that the health of the indexing database needs to be checked:
The DataMiner Agent may fail to start if the indexing database is unavailable.
At startup, elements read active alarm information from the indexing database. Failure to read this data will cause the element to enter an error state and not start up.
Data stored in the indexing database cannot be retrieved, including:
Active or historical alarms
SRM data (e.g. bookings, resources, service definitions)
DOM data (e.g. a low-code app that uses DOM data is unable to display it)
User-Defined APIs are unavailable.
Analytics features are unavailable.
Some DataMiner modules cannot be initialized, such as:
Resource Manager
UserDefinableApiManager
ProcessAutomationManager
Further troubleshooting steps
For detailed guidance on diagnosing and resolving indexing database issues, refer to the following pages:
Troubleshooting tools: An overview of the tools available for monitoring and diagnosing issues related to the indexing database.
Diagnostic procedures: A guide to verifying the health and connectivity of the indexing database, troubleshooting common issues, and resolving shard allocation problems.
Common issues: A list of frequently encountered problems related to OpenSearch database configuration and their potential solutions.
Known issues: An overview of known issues, where you may find indexing database problems that have already been documented, along with potential workarounds or fixes.