Introduction
A multithreaded timer can be used to iterate over a table and process the rows of that table in a multithreaded fashion, making sure that each row in the table is processed in a specified interval.
DataMiner currently allows the use of multithreaded timers to perform multithreaded SNMP, serial (including SSH) or HTTP requests. Optionally, a ping can be executed before the actual request is performed. Alternatively, a multithreaded timer can also be used to just execute logic defined in a QAction using multithreading.
Note
Thread synchronization is needed in the QAction when the same items are set or calls to other processes are executed.
A multithreaded timer is always linked to a table for which the rows will be processed periodically. Typically, each row in this table holds information about a device (such as the IP address).
Every defined timer (i.e. Timer tag in the protocol XML) represents one timer thread that will go off every period as specified in the Time tag. This is the case for conventional timers and multithreaded timers.
For conventional timers, when the timer goes off, it will either add the specified groups to the group execution queue of the protocol thread (in case of groups of type "poll") or it will execute the group immediately (in case of groups that are not of type "poll"). multithreaded timers, however, make use of threads from a thread pool to perform an operation for each row of a table.
To define a multithreaded timer, the "ip", "each" and "threadPool" options need to be specified in the "options" attribute of the timer:
- The first part of the "ip" option defines the ID of the table that contains the rows the multithreaded timer needs to process. The second part defines the 0-based column index that either contains the IP address or the primary key (depending on whether you want to perform a ping operation or execute a QAction).
- The "each" option specifies the period (in ms) that each row should be executed in the table.
- The "threadPool" option defines, among other things, the size of the thread pool.
- For an overview of all the available options of a multithreaded timer, see Timer options.
Finally, a multithreaded timer needs to contain a group of type "poll".
For example, consider the following multithreaded timer:
<Timer id="2" options="ip:2000,1;each:60000;threadpool:20;...">
<Name>Multithread Timer 2</Name>
<Time>2000</Time>
<Interval>0</Interval>
<Content>
<Group>1</Group>
</Content>
</Timer>
This multithreaded timer specifies that every row should be processed once every minute (each:60000).
When the timer goes off, the rows of the table are partitioned into buckets. Each bucket represents a number of rows to be processed in one second. The number of buckets is determined by the "each" option: If "each" is specified as "60000", then 60 buckets will be created.
The size of the buckets depends on the number of rows present in the table: suppose the table contains 180000 rows; this means that, on average, 3000 rows (180000 rows / 60 s) need to be processed every second. The rows of the table will be spread over these buckets until each row is assigned to a bucket.
Note
When the element log level is set to level 3 or higher, the log file will include an overview of the number of buckets and the size of each bucket as follows:
Spreading of Items: 5 groups, 100 items
00000000: count = 00000020
00000001: count = 00000020
00000002: count = 00000020
00000003: count = 00000020
00000004: count = 00000020```
In the logging, "groups" refers to the buckets, and "items" refers to the table rows.
The number of buckets to process when the timer goes off is determined by the specified timer time. In the example, as the time is set to two seconds (<Time>2000</Time>), two buckets will be taken to be processed.
Note
As the buckets are calculated on a per-second basis, it is advisable to set the timer time to either 1000 ms (which is the recommended value) or multiples of 1000 ms (with a maximum of 5000). The smaller the value, the more equal the row processing will be spread.
The items in the selected buckets are then added to a queue representing all items that need to be handled by threads of the thread pool.
Note
- You can limit the number of items that can be added to the queue. This is done using the "queueSize" option of the "threadPool" option. In case this limit is reached, items will no longer be added to the queue. An alarm will be generated and a message will be added to the element log as follows:
The thread-pool([ID]) with [thread pool size] threads, contains more than [thread pool queue size] items to be executed. - Before a bucket is added to the queue, DataMiner first verifies whether a previous execution of the bucket is still present in the queue. If this is the case, the bucket will not get added again.
The following figure illustrates how table rows get partitioned and assigned to a bucket. These buckets then get added to the processing queue.

Threads of the thread pool will then process the items in the queue. (The items in the queue denote the primary key of the row to process.)
Note
To know the current size of the thread pool, the "dynamicThreadPool" option can be used.
The thread will perform the following steps to process a row:
It obtains the required data from the row it is going to process (using the primary key that is mentioned in the item on the queue). The data that is obtained depends on the options that are configured for the multithreaded timer.
- The cell referred to in the "ip" option
- The cell referred to in the "ignoreIf" option
- The cell referred to in the "instance" option
- If the Group uses the
col:<columnIdx>:<defaultGroupId>, notation, the value of the referred column for the row is retrieved. (For more information about this notation, see Timer.Content.Group.)
If the Group uses the
col:<columnIdx>:<defaultGroupId>, notation and the cell refers to a group, this group is loaded.If the "qactionBefore" option is used, the referred QAction is executed.
Note
As the relevant row data is already obtained in the first step, it is not useful to alter this data from the QAction that is referred to by the "qactionBefore" option, as the updated values will only be apparent the next time the row is being processed.
If the "ignoreIf" option is used, and the ignore condition matches (i.e. the cell value matches the specified value in the "ignoreIf" option, or the cell is not initialized), no request will be performed and the QAction to process the response will also not be executed. Execution will jump to executing the QActions defined in the "qactionAfter" option.
If the "ping" option is used, the ping is executed.
If the ping succeeded, or the "continueSnmpOnTimeout" option is set to "true", the request will be executed in the next step. Otherwise, no request will be executed. However, the QAction to process the response result will be executed where the result will now mention "NO POLLING OCCURED" (sic) and the error will denote "PING FAILED". (For information on all configuration options, see ping).
Depending on the type of the connection that is defined for the group (this is either by default the main connection, or a connection defined in the Group@connection attribute):
- For serial (single) or HTTP connections, the content returned by the QAction referred to by the "qactionBefore" option is used to perform a protocol notify call that will execute the request (via the SLPort process).
- For SNMP connections, a raw SNMP get is performed using the contents of the group (via the SLSNMPManager process).
Note
This is why a poll group always needs to be added to a multithreaded timer as this allows DataMiner to obtain the type of connection.
The QAction to process the response is executed.
If the "qactionAfter" option is used, the referred QAction is executed.
For SNMP, the group defines the OIDs to request:
<Group id="2000" connection="0">
<Name>SNMP Poll Group</Name>
<Content multipleGet="true">
<Param>1000</Param>
<Param>1001</Param>
<Param>1002</Param>
<Param>1003:single</Param>
</Content>
</Group>
Note
Keep the following in mind when performing SNMP requests:
- The SNMP parameters need to have the "loadOID" option.
- A table (array) parameter cannot be used in this group; when tables are polled, this also needs to be done through a single parameter with "loadOID".
To process the response, a QAction is defined that has the options="group" attribute and the triggers attribute set to the ID of the group mentioned in the multithreaded timer.
<QAction id="1011" name="Send Request" encoding="csharp" options="group" triggers="1011" row="true">
Often, a QAction is used to perform some additional logic. This is then done by the QAction referred to by the "qactionAfter" option.
The following figure illustrates the general concept for SNMP:

For serial and HTTP requests, the request is constructed in a QAction referred to by the '"qactionBefore" attribute. The group mentioned referred to by the multithreaded timer is then empty:
<Group id="1">
<Name>Multithread Group 1</Name>
<Description>Multithread Group 1</Description>
<Type>poll</Type>
<Content></Content>
</Group>
The QAction that constructs the request object then has an entry point method that returns an object array:
public class QAction
{
public static object[] Run(SLProtocolExt protocol){ ... }
}
This returned object will be used to perform the actual request. (For more information on the expected structure of this object, refer to Serial or HTTP.)
Similar to SNMP, to process the response for serial and HTTP, define a QAction that has the options="group" attribute and the triggers attribute set to the ID of the group mentioned in the multithreaded timer.
<QAction id="1011" name="Send Request" encoding="csharp" options="group" triggers="1011" row="true">
(For more information on how to process the response data in this QAction for the different connection types, refer toSNMP, Serial or HTTP.)
Finally, a QAction can be used to perform some additional logic. This is then done by the QAction referred to by the "qactionAfter" option.
The following figure illustrates the general concept for serial and HTTP:

Please note the following:
The requests performed by the multithreaded timer (e.g. SNMP requests or ping) have no impact on the element state. I.e. if a request times out this will not have an impact on the state of the element.
The group mentioned in the multithreaded timer serves to detect the connection to use. This group does not actually get executed as is the case with conventional timers. Therefore, conditions on a group do not work with multithreaded timers. (Conditions on QActions, however, do work with multithreaded timers.) Similarly, "before group" triggers are also not supported with multithreaded timers.
When the timer goes off, first the defined "before timer" triggers are executed. For example, for the following trigger, this means that trigger 1 will go off every 2 seconds.
<Trigger id="1"> <Name>Initialization</Name> <On id="2">timer</On> <Time>before</Time> ... </Trigger> <Timer id="2" options="ip:1000,2;each:60000;threadpool:10;..."> <Name>Multithread Timer 1</Name> <Time>2000</Time> <Interval>0</Interval> <Content> <Group>1</Group> </Content> </Timer>As already stated, the specified timer time has an impact on the number of buckets (and therefore the number of items that are added to the queue) when the timer goes off.
The following graph illustrates the row processing. At time 0, threads from the thread pool are used to process queued items until all items in the queue are processed. DataMiner then waits until the Timer.Time has passed before starting the processing of the next batch of items (2s in this example).
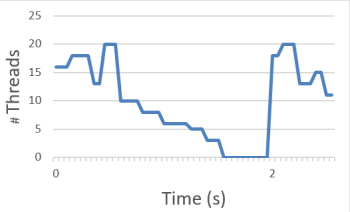
The pollingRate option can be used to spread the execution of the rows in each chunk.
Suppose a table contains 10 000 rows and the "each" option is set to 100 000 ms; this means that the timer should execute 10 000 rows/100 s = 100 rows per second. When pollingrate is not defined, this means that at the start of each second, all threads of the thread pool would be activated to process these rows.
The "pollingrate" option ensures that the processing of these rows is more equally spread over time. This is done by using a counting semaphore that limits the number of threads that can be used simultaneously.
For example, “pollingRate:15,3,3” means that a counting semaphore with max count of 3 will be used, which will release at most 3 threads every 15 ms. For more information about this option, see pollingRate.
Caution
Proper configuration of a multithreaded timer is very important, as it can have a major impact on CPU usage.
Timer.Content.Group
For multithreaded timers, the Group tag can contain the following syntax:
col:<columnIdx>:<defaultGroupId>
- columnIdx: Specifies the 0-based column index of the column that specifies the ID of the group to use.
- defaultGroupId: Specifies the ID of the default group ID. This default group is used in case the cell that is referred to does not denote an existing group ID.
Example:
<Group>col:5:1</Group>
Examples
In the following example, QAction 1000 is executed for every row in table 800:
<Timer id="1" fixedTimer="true" options="ip:800,1;each:10000;threadPool:100;qactionBefore:1000">
In the following example, a ping is executed for every row in table 1000 using the IP found in columns idx 30:
<Timer id="4" options="ip:1000,30;each:3600000; threadPool:100;pollingRate:15,3,3; ping:rttColumn=28,
timestampColumn=29,size=0,ttl=250,timeout=3000,type=icmp,continueSnmpOnTimeout=false;qactionBefore:
14">
In the following example, 5 pings will be sent to the device, of which only the last 4 will be taken into account for the KPI calculation. The 50% worst results of these last 4 will also be filtered out, so that effectively only 2 of the results will be used for the KPI calculation.
<Timer id="1" options="ip:1000,1;each:5000;pollingRate:15,3,3;threadPool:300,5,201,202,203,204,
213,30000;dynamicThreadPool:227;ping:rttColumn=7,timestampColumn=5,size=0,ttl=250,timeout=1500,
type=winSock,continueSnmpOnTimeout=true,jitterColumn=8,latencyColumn=9,packetLossRateColumn=10,
amountPackets=5:amountPacketsMeasurements=4,excludeWorstResults=50">
...
</Timer>
Note
From DataMiner 9.5.1 (RN 14522) onwards, if only one packet is sent, this will be displayed as a timeout, as jitter cannot be calculated based on 1 ping result. In earlier versions, a jitter of 0 ms is displayed.
The following example makes use of the options to calculate the jitter, latency and packet loss rate.
<Timer id="1" options="ip:1000,1;each:5000;pollingRate:15,3,3;threadPool:300,5,201,202,203,204,
213,30000;dynamicThreadPool:227;ping:rttColumn=7,timestampColumn=5,size=0,ttl=250,timeout=1500,
type=winSock,continueSnmpOnTimeout=true,jitterColumn=8,latencyColumn=9,packetLossRateColumn=10,
amountPacketsMeasurements=4">
<Name>Fast timer</Name>
<Time>1000</Time>
<Interval>0</Interval>
<Content>
<Group>1</Group>
</Content>
</Timer>