Configuring the master nodes
Note
Elasticsearch is only supported up to version 6.8, which is no longer supported by Elastic. We therefore recommend using Storage as a Service instead, or if you do want to continue using self-managed storage even though this is not recommended, using OpenSearch.
Important
A correct master node configuration is extremely important since master nodes logically determine which nodes are part of the cluster. This page is therefore a must-read before you set up any Elasticsearch clusters.
Tip
Before you set up an Elasticsearch cluster, first read how to Configure the master node. Then you can start Adding Elasticsearch cluster nodes.
A master node is responsible for lightweight cluster-wide actions such as creating or deleting indices. It also tracks which nodes are part of the cluster and decides which shards to allocate to which node. Basically, a master node decides where data gets stored.
An Elasticsearch cluster can only have one master node. If, on the other hand, there is no master node, there is no Elasticsearch cluster and no read or write operations can be performed.
It is of the utmost importance for a cluster to have a stable master node.
Hardware requirements
There are no specific requirements for master nodes. The master node should be a stable node, so making sure it meets the minimum requirements is an absolute must. A master node might use a bit more CPU power, but this should not have a huge impact.
Which node will become the master node?
It is not possible to choose which node will be the master node. It is only possible to choose which nodes are eligible to become master. An election process will then decide which node will become the master node.
In the elasticsearch.yml file, all nodes that are eligible to become master should have their node.master property set to true. If only one node is marked "node.master:true", then that node will always become the master node.
Note
By default, all nodes will have their node.master property set to true.
Preventing a split-brain situation
Let us assume that we have a situation like the one depicted below: 2 nodes, both eligible to become master, of which one is currently acting as master node.
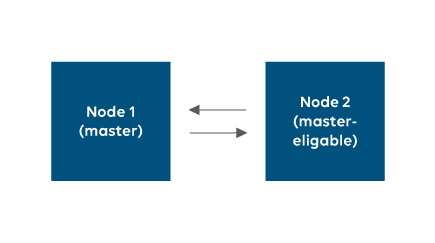
At some point, while both nodes are busy synchronizing, reading data and writing data, network connections are lost.
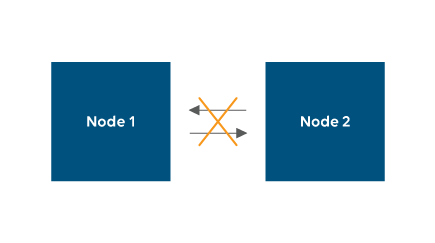
As they can no longer detect each other, both nodes will assume the other one is offline and, as a result, they will both promote themselves to master node. In essence, there will now be 2 clusters with a single master node each.
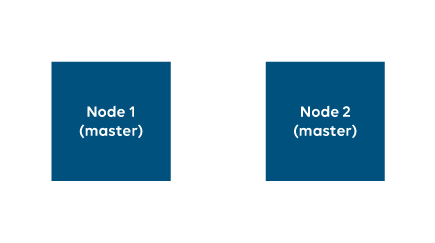
This is a so-called split-brain situation. Both single-node clusters will now each receive requests to read and write the same data.
When, at this point, the network issue described above is resolved, and both clusters become one again, the nodes will try to synchronize their data. Unfortunately, data mismatches due to the split-brain situation will prevent the data from getting synchronized successfully.
The best practices listed below should help you avoid this kind of situations.
Best practices
2 nodes
In case there are 2 nodes, you can potentially get into a split-brain situation like the one described above. To prevent this kind of situation, it is advised to only make one of the two nodes eligible to become master. This way, when the non-master node is offline, the cluster will still behave correctly. However, when the master node is offline, the cluster will no longer accept requests to read or write data. Hence, a 2-node cluster should not be considered an option since it has only a 50 percent chance on redundancy.
3 nodes
Compared to a 2-node cluster, a 3-node cluster can guarantee full redundancy.
Let us assume we have a 3-node cluster and that all three nodes are eligible to become master ("node.master:true") ...

... and that node 3 is either offline or no longer connected to the other nodes due to a network issue ...
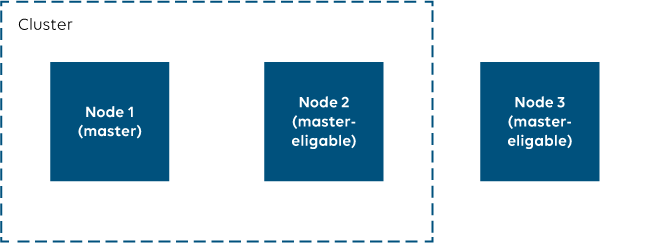
At this point, node 3 could decide to become a separate cluster.
However, by setting discovery.zen.minimum_master_nodes to 2 in the elasticsearch.yml files of the three nodes, this will not happen. This setting defines how many potential master nodes must be online before a cluster is formed. If it is set to 2, then node 1 and 2 will each notice that there are still 2 potential master nodes online in the cluster. A master node election procedure will then promote one of the two nodes to master node and a new functional 2-node cluster will be up and running. Node 3 will not find any node that is eligible to become master. Hence, it will not create its own cluster and will not accept requests to read or write data.
More than 3 nodes
In general, when you have more than 3 nodes, you can configure the cluster in the same way as a 3-node cluster and set the node.master property of any additional node to false. There is no real need to increase the number of nodes eligible to become master, except in certain special cases. In these special cases, as a rule of thumb, you can define an N amount of potential master nodes and set discovery.zen.minimum_master_nodes to (N + 1)/2.
Note
If the nodes are spread over different data centers, zones, racks, and so on, we recommend setting up Allocation Awareness in the Elasticsearch cluster.