Dedicated clustered storage
Important
This architecture is supported but not recommended. Instead, we recommend using Storage as a Service (STaaS).
If you do not use the recommended Storage as a Service (STaaS) setup but instead choose self-managed storage, dedicated clustered storage is the most typical setup. The storage nodes can be either on premises or in the cloud, or a mix of both. You will need:
One Cassandra cluster for the entire DataMiner System (DMS). Unlike setups with a Cassandra cluster per individual DataMiner Agent (DMA), this allows the database to be scaled for the entire DMS at once.
One OpenSearch cluster for the entire DMS. While an Elasticsearch cluster can also be used, Elasticsearch is only supported up to version 6.8. As this version is no longer supported by Elastic, this is not recommended.
Tip
For information on how to implement a setup like this based on an existing DataMiner setup with SQL or Cassandra databases per DMA, see Migrating the general database to a DMS Cassandra cluster
Note
- In the setups described below, a "machine" or "compute node" can be a virtual machine or a physical server. Every machine must meet the minimum requirements detailed in DataMiner Compute Requirements. In the images illustrating the setups, the dark-blue line indicates a cluster of nodes, the gray line indicates a compute node, and the light-blue line indicates a regional boundary (high latency).
- Using managed services from a cloud provider instead of on-premises databases is supported from DataMiner 10.3.0/10.3.3 onwards. Using an on-premises OpenSearch database is also supported from DataMiner 10.3.0/10.3.3 onwards.
Single DMA setups
We recommend running DataMiner, Cassandra, and OpenSearch on dedicated machines. If you want to use cloud storage instead, we recommend switching to Storage as a Service (STaaS). Setups with Amazon Keyspaces Service, Azure Managed Instance for Apache Cassandra Service, and Amazon OpenSearch Service are considered deprecated as of DataMiner 10.3.0 [CU9]/10.3.12.
An on-premises OpenSearch cluster must have an uneven number of nodes, running on Linux machines. This means that if you want to leverage replication or have a redundant system, you need at least 3 nodes.
Instead of OpenSearch, you can also use Elasticsearch. However, Elasticsearch is only supported up to version 6.8, so this is not recommended.
For a Cassandra cluster, any number of nodes can be used, running on Linux machines. To get an idea of how many nodes would be required for your system, use the node calculator.

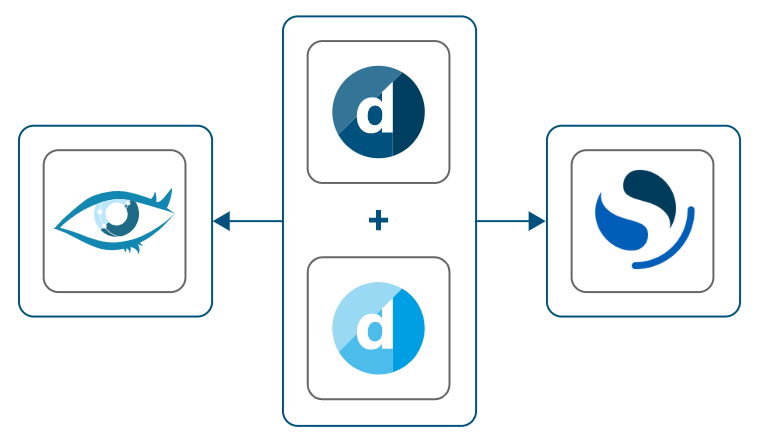
Recommended on-premises setup: DataMiner, Cassandra, and OpenSearch hosted on dedicated machines
In a development environment with limited load, it is possible to host DataMiner, Cassandra, and OpenSearch on one Windows machine. In this case, OpenSearch and DataMiner must be installed on a separate disk or partition. However, note that this is not recommended for normal production environments. For Cassandra, we recommend using WSL, as Cassandra is no longer supported on Windows starting from Cassandra 4.x and DataMiner 10.4.x. However, keep in mind that using Storage as a Service (STaaS) instead will greatly reduce CPU and memory usage, especially for smaller setups.
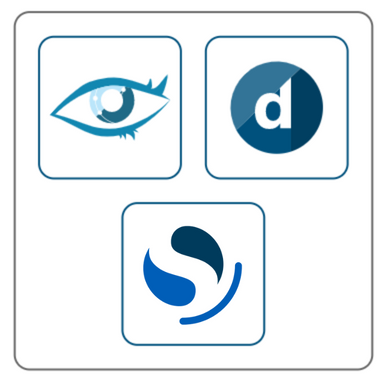
Development setup: DataMiner, Cassandra, and OpenSearch hosted on the same machine
Multiple DMA (non-Failover) setups
In case you have more than one DataMiner Agent, you can scale both on DataMiner level and on database level. If you want to use cloud storage instead, we recommend switching to Storage as a Service (STaaS). Setups with Amazon Keyspaces Service, Azure Managed Instance for Apache Cassandra Service, and Amazon OpenSearch Service are considered deprecated as of DataMiner 10.3.0 [CU9]/10.3.12.
An on-premises OpenSearch cluster must have an uneven number of nodes, running on Linux machines. This means that if you want to leverage replication or have a redundant system, you need at least 3 nodes.
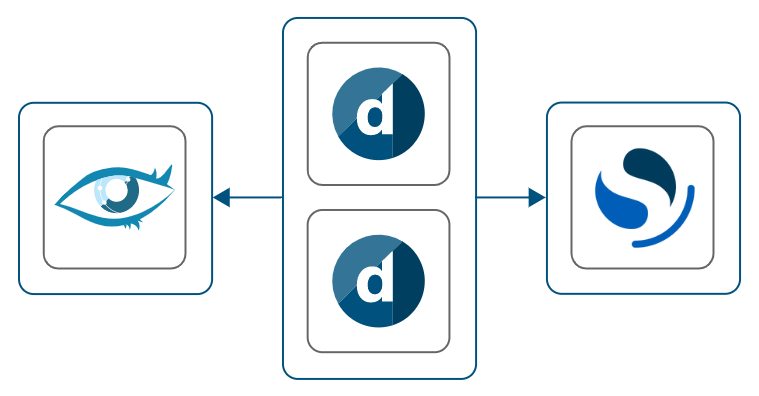
Instead of OpenSearch, you can also use Elasticsearch. However, Elasticsearch is only supported up to version 6.8, so this is not recommended. It is also possible to host a DataMiner and Elasticsearch node on the same machine. In this case, Elasticsearch and DataMiner must be installed on a separate disk or partition. Note that in that case it is not required to install an Elasticsearch node on every single DataMiner node. While compute resources can be shared, logically there still is a separate DataMiner node cluster and Elasticsearch cluster.
For Cassandra, any number of nodes can be used, running on Linux machines. To get an idea of how many nodes would be required for your system, use the node calculator.
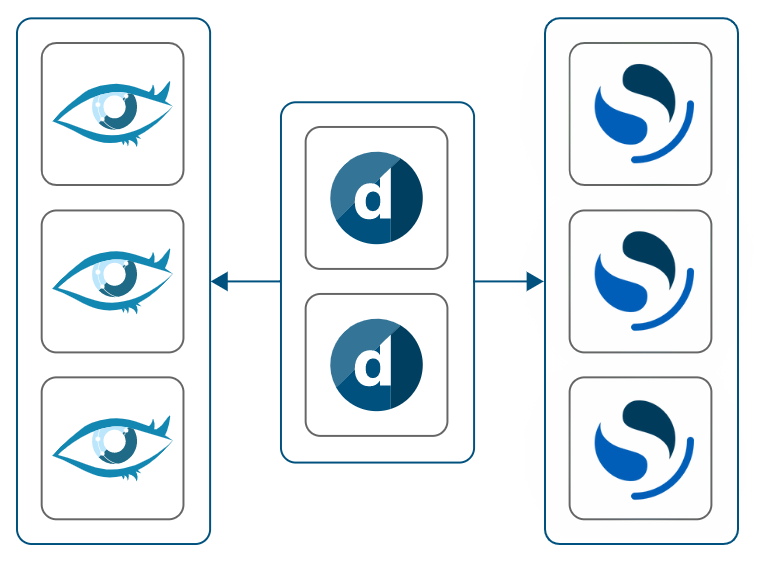
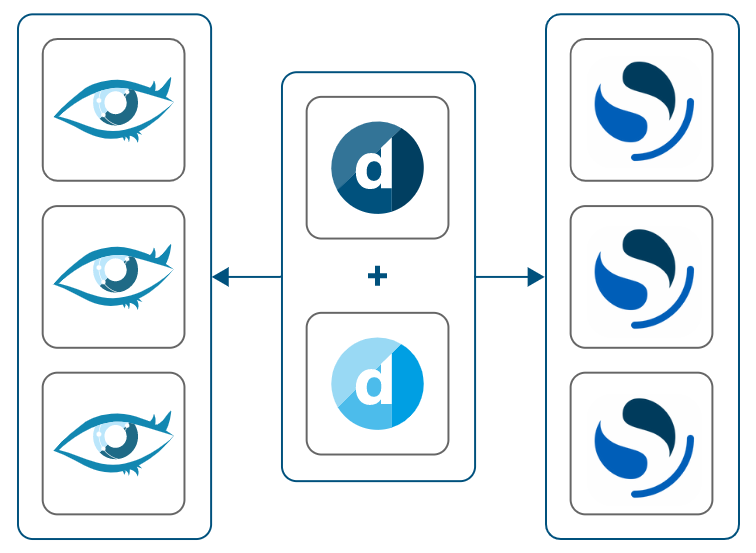
Recommended on-premises setup: DataMiner, Cassandra, and OpenSearch hosted on dedicated machines, with a minimum of three OpenSearch nodes
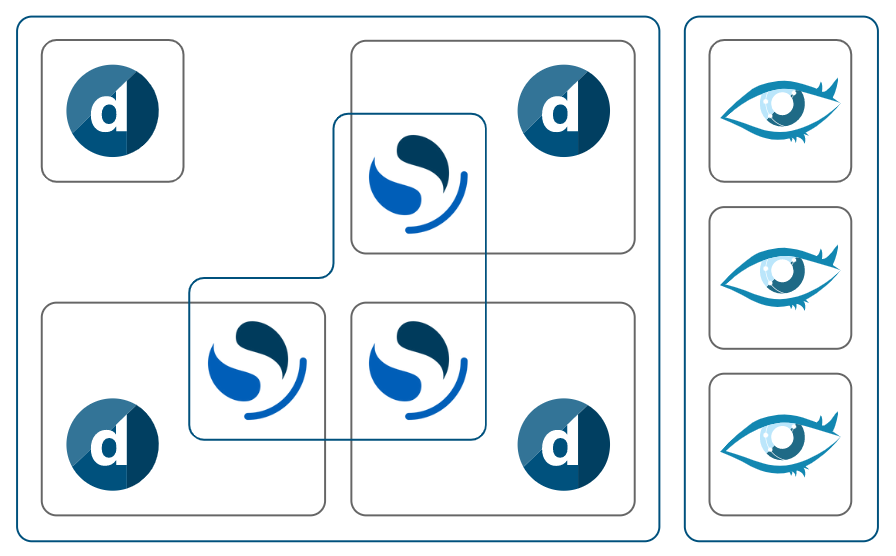
Setup with OpenSearch and DataMiner sharing resources
Two DMAs using a single Cassandra and OpenSearch node running on dedicated machines
Failover setups (without geo-redundancy)
A Failover setup is similar to the previously mentioned setups. You can consider the Failover pair to be like one DMA in the DMS. This setup should at the very least consist of two DataMiner machines, one OpenSearch or Elasticsearch machine, and one Cassandra machine. However, if the Cassandra or OpenSearch/Elasticsearch machine are no longer available in this setup, you will no longer be able to start DataMiner, so this is not recommended for redundancy setups. Also, as Elasticsearch is only supported up to version 6.8, using Elasticsearch is not recommended.
To be fully hardware-redundant, we recommend at least three machines hosting OpenSearch nodes, two machines hosting the DataMiner Failover pair and three machines hosting Cassandra nodes. More Cassandra and OpenSearch nodes can be needed depending on the load on your system. Check the node calculator for more information.
While hosting Elasticsearch and DataMiner nodes on the same machine is already not recommended in general, this should definitely not be done in a Failover setup, as it will not allow you to get the desired resilience.
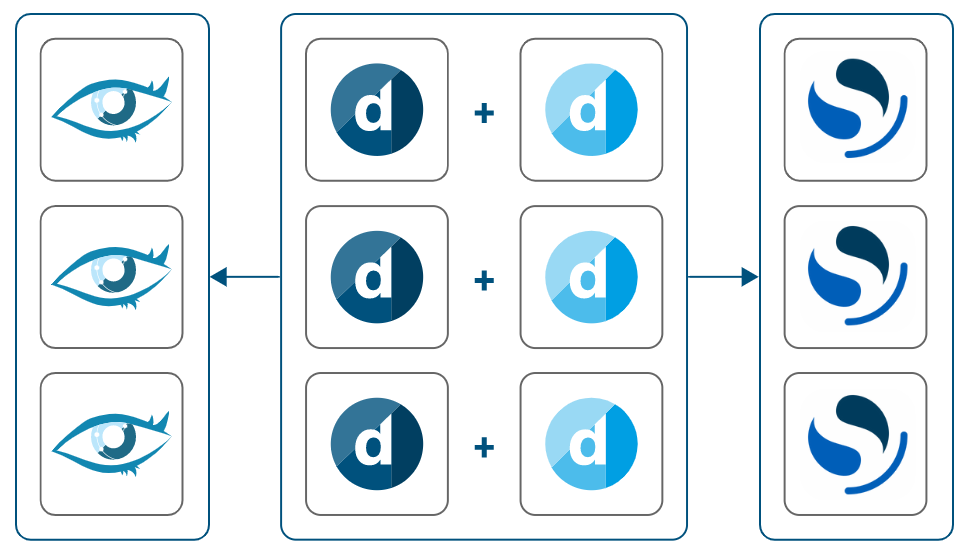
DataMiner Failover pair using a Cassandra and OpenSearch database running on dedicated machines
Minimum recommended on-premises setup for a fully redundant system
DataMiner System consisting of three Failover pairs with Cassandra and OpenSearch nodes running on dedicated machines
Failover setups (with geo-redundancy)
To achieve geo-redundancy and reduce latency between DMAs deployed across the globe, typically data center setups are used. In case you need a setup with multiple data centers deployed worldwide, please contact Skyline. For geo-redundant systems, a stable network connection that has low latency is required between the sites. Setting up an OpenSearch/Elasticsearch cluster across high-latency nodes is not advised, as this could compromise proper functionality. This means that it is not possible to simply take OpenSearch/Elasticsearch nodes and spread them out over two or more locations if there is high latency between those locations. This restriction specifically applies to latency between the openSearch/Elasticsearch nodes, not between the DataMiner nodes and the OpenSearch/Elasticsearch nodes.
Failover setups with Amazon Keyspaces Service, Azure Managed Instance for Apache Cassandra Service, and Amazon OpenSearch Service are considered deprecated as of DataMiner 10.3.0 [CU9]/10.3.12. If you want to use cloud storage, we recommend switching to Storage as a Service (STaaS), which includes geo-redundant options.
The figure below illustrates the recommended minimum setup for geo-redundancy with on-premises machines. For Cassandra, the built-in NetworkTopologyStrategy is used to configure geo-redundancy. For OpenSearch, one cluster is configured for which the nodes are spread over three zones, two of which host the data, while the third zone has a single node that does not handle any data and functions as a tie-breaker for cluster configuration. The tie-breaker node can be cloud-hosted if the latency is sufficiently low (below 50 ms). To ensure that OpenSearch understands which node is a data node on which location, shard allocation awareness must be configured.
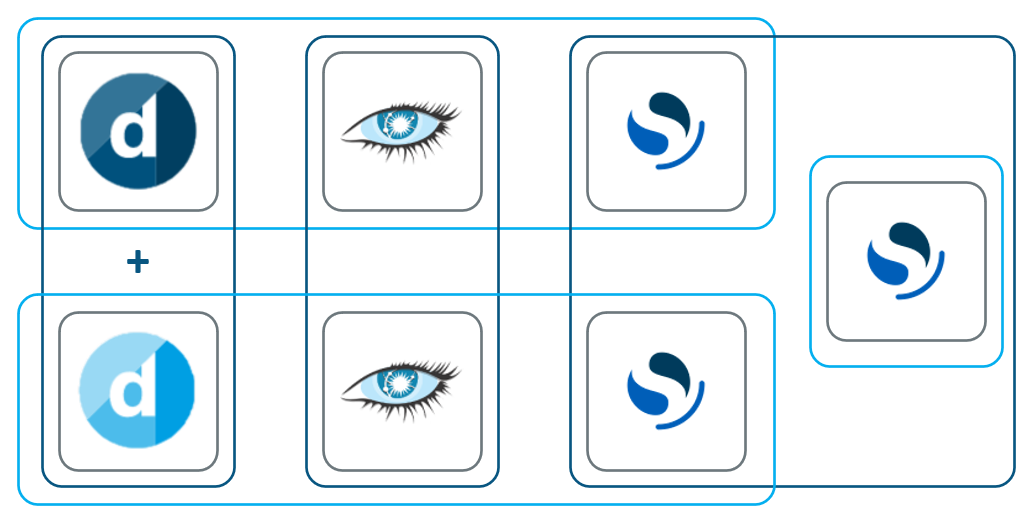
Recommended minimum setup for a geo-redundant system