The DataMiner Service and Resource Management stack
Each of the DataMiner SRM use cases relies on a combination of different DataMiner modules. The SRM stack consists of seven DataMiner modules that are easily deployed on all DataMiner nodes in the system. Different SRM use cases rely on a different subset of these modules, as illustrated below.

Scheduling Engine
The Scheduling Engine executes scheduled actions precisely, reliably, and on time. The engine can trigger a variety of DataMiner actions, including any and all Automation script executions needed by DataMiner SRM. The Scheduling Engine is the actor behind any orchestration, whether this is loading a profile on a resource in the Resource Orchestration use case or executing a service life cycle state change.
The Scheduler timeline can be visualized in Visual Overview or in dashboards and low-code apps. The timeline components not only support rich schedule visualization options but also facilitate control surface user actions, such as selecting a time range in one click. A built-in bookings timeline is also available in the Bookings module in DataMiner Cube.
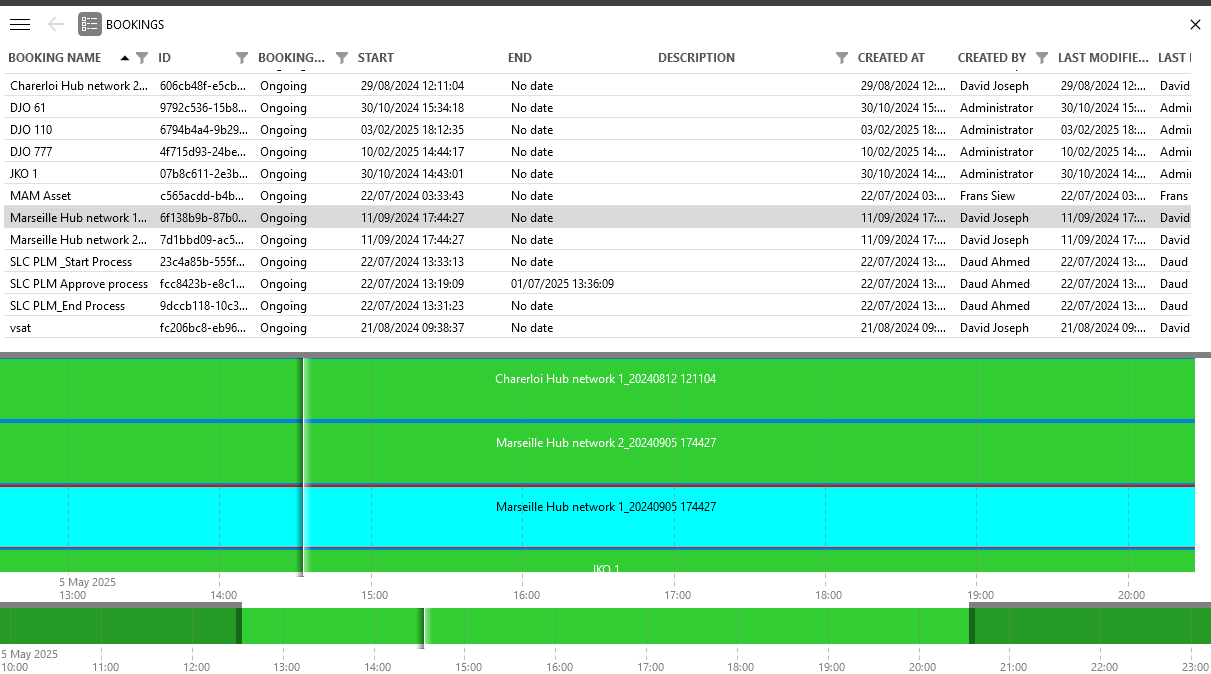
Bookings module in DataMiner Cube 10.5.5
To prevent alarm fatigue in operation teams, you can also apply schedule-aware monitoring. Alarm template configurations can be included in various Profile-Load Scripts (PLS) and/or Life cycle Service Orchestration (LSO) scripts. This way, when a profile is loaded on a resource based on the schedule, an alarm template can be loaded that only monitors the health status of the resource. Similarly, on service life cycle orchestration level, a switch to a different LSO state can go hand in hand with updated alarm monitoring.
The scheduling engine supports a wide range of possibilities. Bookings can be scheduled to happen just once, or they can be made permanent. DataMiner SRM supports a variety of LSO state transitions, including pre- and post-roll LSO state changes, as well as booking events. This allows you to streamline even the most complex event schedules.
Tip
For more information:
- Demo video: How To Schedule your Resources using SRM

- Various Scheduler-related videos are available in our video collection
- Various Scheduler use cases with screenshots are available in the use case library
Resource Manager
Resources in DataMiner can represent any entity with limited availability, capacity, or capabilities, including for example physical inventory, network ports, staff, rooms, desks, and even non-tangible assets like IP addresses or software licenses. Each resource can be defined with a customized set of capabilities (e.g. SD, HD, or UHD) and various capacity constraints (e.g. a network interface may only be booked up to 90% of its bandwidth).
A resource can be booked only partially or in its entirety, and it may even be booked multiple times during a given timeframe. Resource behavior can be fully customized to the needs of the operator and the managed infrastructure. To get a complete overview of all resources in the system and to easily add or manage resources, you can use the Resources module in DataMiner Cube.
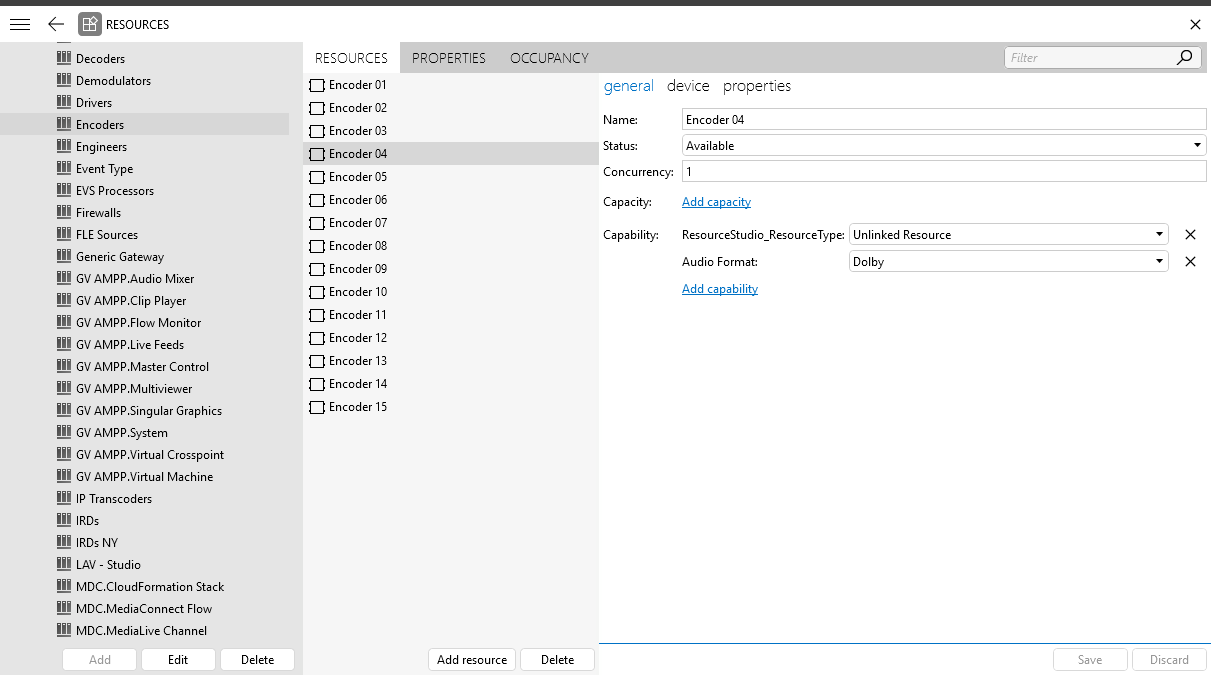
Resources module in DataMiner Cube 10.5.5
DataMiner Resource Manager controls and monitors the availability of all resources in DataMiner SRM. This means that it prevents the use, or the booking ahead of time, of any resource that is not available in the desired time slot or time slot series. It is the central intelligence unit that ensures that not only all current services can rely on the availability of the booked resources, but also all planned modified services and new service launches in the future.
Automation Engine
The DataMiner Automation engine performs all automation tasks in the ecosystem. Its pronounced open architecture enables operators to easily create scripts and customize script behavior to their specific environment whenever needed. To create scripts, they can either use the built-in Automation module in DataMiner Cube, or make use of the DataMiner Integration Studio (DIS).
Once created, scripts can be triggered in a variety of ways, ranging from manual operator initiation to event-based, change-based, or scheduled execution (through integration with the Scheduling Engine).
Even if tasks are automated, the operator always remains in control. Not only is there a full audit trail of the executed tasks, but operators can also opt to interact with the Automation engine at runtime. DataMiner interactive Automation scripts can be set up to prompt for operator input, which is then used to automate further actions.
Automation scripts can be developed, tested, and deployed at runtime. Using built-in version control and quality checks during deployment (with DIS and CI/CD using our dedicated workflows), operators can easily use DevOps practices to respond to the rapid changes in today's networks, data centers, and service offerings.
By fully automating operating and business procedures or workflows, operational expenses can be drastically reduced. Automation scripts can be used in a lot of applications such as intelligent backup and service-healing routines, guided troubleshooting for operators, automatic configuration, provisioning of services, etc.
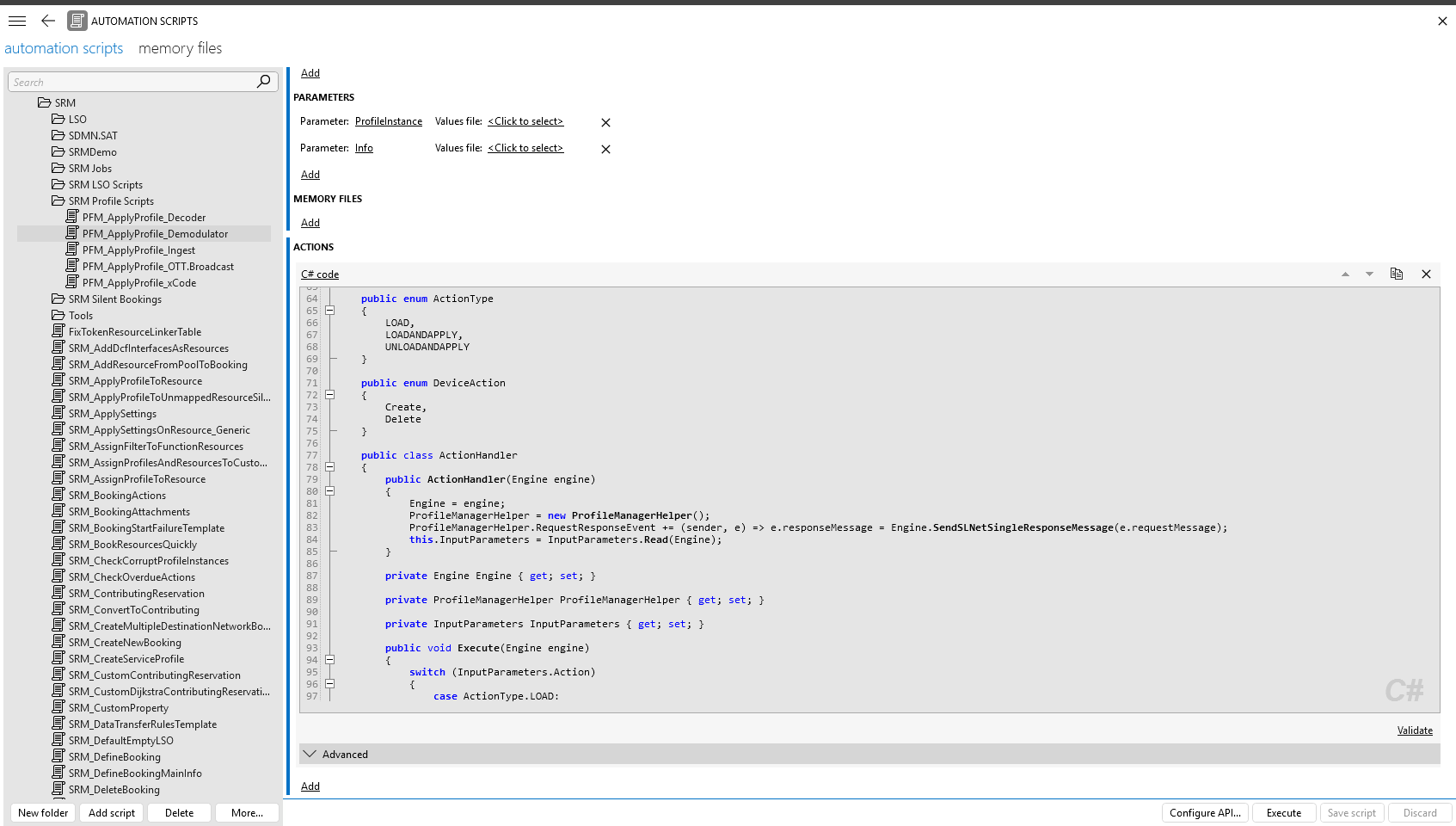
Automation module in DataMiner Cube 10.5.5
Tip
Various Automation-related videos are available in our video collection, including an introduction to the basics of DataMiner Automation snippets.
Profile Manager
Profiles in DataMiner can be used to configure complex resources repeatedly and reliably. This is typically done using Profile-Load Scripts (PLS), which execute the necessary parameter sets on a resource in an ordered and controlled manner via its connector in DataMiner.
Essentially, profiles act as a mediation layer between the operations workflows and the infrastructure's technology details. They consist of a set of parameters and the values that need to be applied to them, independent of the underlying technology. Think for example of a profile to tune a satellite receiver: operators can add parameters required for any branch of satellite receiver, such as the center frequency, roll-off factor, modulation standard, etc. The Profile-Load Scripts then take care of translating those profile parameters to the underlying technology. However, simple profiles may even be used without such scripts. In the Profiles module in DataMiner Cube, you can get an overview of all the profiles available in the system and add or update your profiles without any need for scripting.
Aside from configuration parameters, a profile can also include a customized list of capacities and capabilities. For example, an HD profile of 4 Mbps needs an HD encoder, and an SD profile of 1.5 Mbps needs an SD-only capable encoder and a limited network capacity only. Corresponding capacities and capabilities should be configured on the resources in this case, so that DataMiner will be able to check if a resource meets the capability requirements asked for in the profile, and it will be able to reduce the capacity of the resource while it is in use.
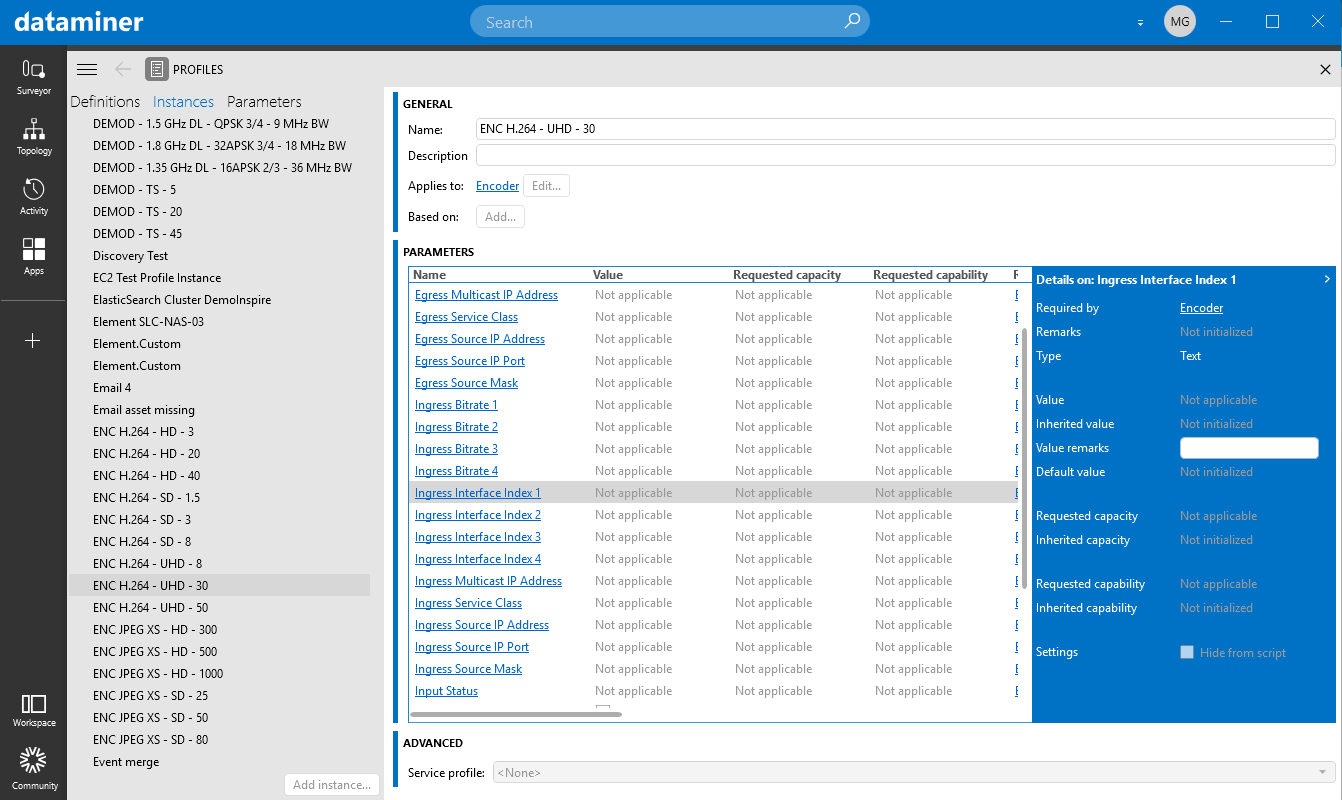
Profiles module in DataMiner Cube 10.5.5
Virtualization Engine
Network Function Virtualization (NFV) is becoming a commodity in modern network and cloud infrastructures. DataMiner virtual functions smoothly map those VNF instances (a.k.a. microservices). The ultimate goal of NFV is to fulfill one specific function very well, and just that.
DataMiner SRM has adapted this approach and extended it to traditional software appliances and hardware products. Appliances and hardware products typically combine many elementary "virtual functions" in a single product. For example, a media transcoder has an IP input function, a video transcoder function, a number of audio transcoder functions, and an IP streaming output function. Packaging all functions together in a single product makes it hard for the operators to use bits and pieces of that product according to the needs of the moment, let alone when they need to schedule the resource up front.
With DataMiner virtual functions, the elementary functional capabilities of a complex product are exposed as individual, elementary resources that can be monitored, configured, and used in DataMiner SRM. Moreover, as different technologies can expose the same kinds of functions (i.e. the same profiles can be applied to them), DataMiner virtual functions truly make service workflows independent of the underlying infrastructure vendor or model.
Network Manager
The DataMiner Network Manager calculates paths across any network, independently from the technology (IP, SDI, L-band, etc.) or vendor used for that network. Path calculation even runs across multiple technologies (hybrid). The calculation itself is cost-based (Dijkstra). The definition of "cost" is completely customizable and can be very broad. In DataMiner, segments can have a real cost value, but the cost can also be a representation of the operator preferences (e.g. interfaces to a PoP that is only used for emergency situations may be configured with a high cost).
In addition, path calculation in DataMiner can account for additional monitored status info and KPIs. For example, interfaces can be dynamically excluded from path calculations in case they have the Admin State "down", if they have alarms, or if they already have a heavy traffic load. Many other features can be configured, such as diverse path routing for red and blue connections, manual node selections, and much more.
When new services are set up, the Network Manager can check if there is sufficient bandwidth capacity available in the network. To do so, it checks the booked capacity for each individual network interface within the requested schedule time slot. Once a network path has been found that has enough capacity to accommodate the service for its entire duration, this bandwidth can be booked to make sure that it can no longer be consumed by other services that still need to be set up, in order to avoid conflicts and service interruptions.
To allow you to keep track of flows throughout your network, DataMiner builds up a database of as-engineered flows based on the paths it calculates during service provisioning. At the same time it can be configured to extract the actual flows running on the network ("as-is"). The "as-is" and the "as-engineered" flows can then be easily compared, for example for troubleshooting.
Service Manager
First-rate from the first time
DataMiner Service Manager offers a full-fledged service layer on top of the individual network resources. Service Manager uses DataMiner service definitions, which act as templates that enable quick service creation. Service definitions specify the required resource types and their interconnections for a certain service. In the Services module in DataMiner Cube, you can create service definitions by dragging and dropping network functions on a canvas and connecting them as desired.
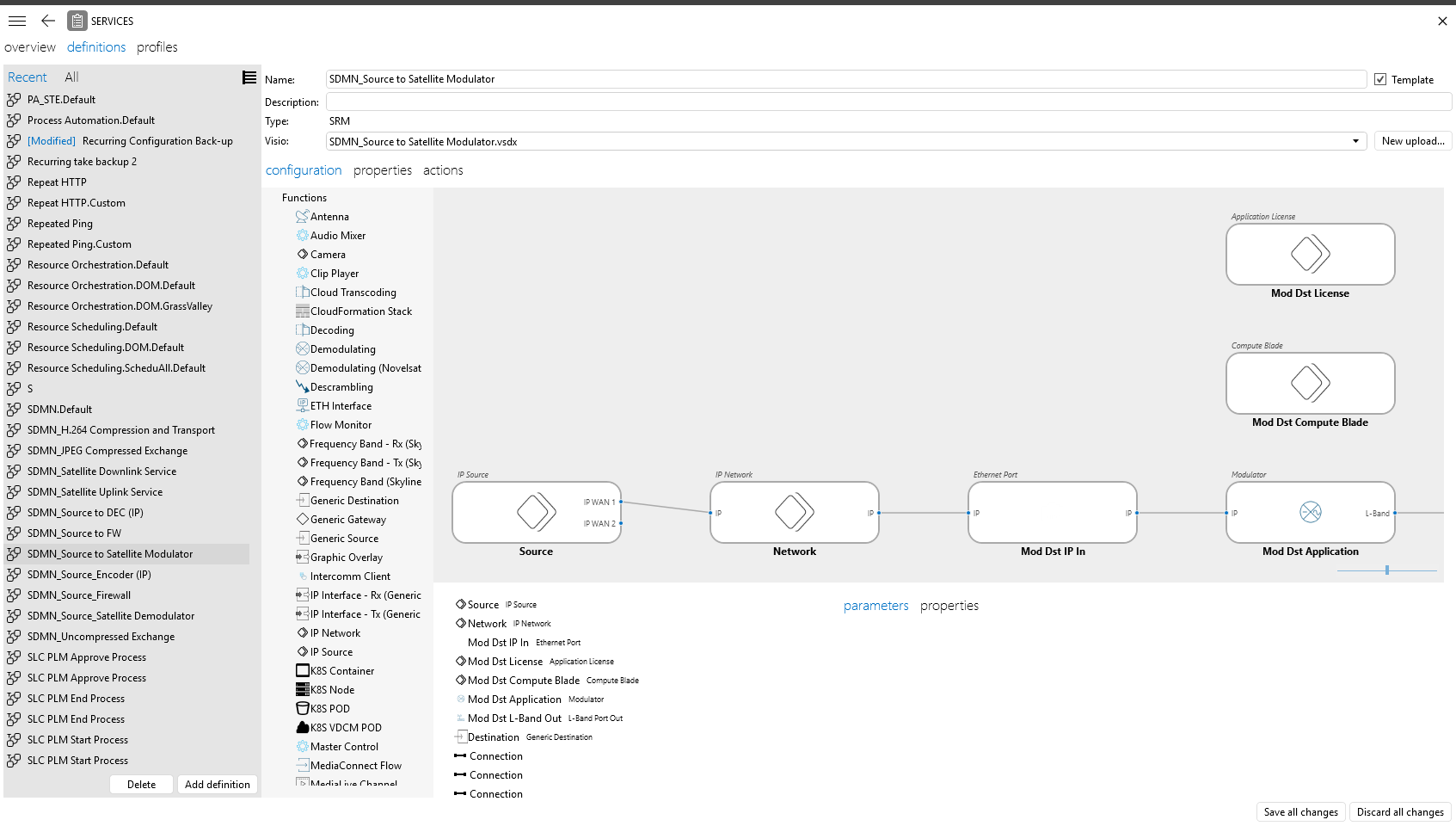
Service definition in the Services module in DataMiner Cube 10.5.5
In the out-of-the-box Booking Manager app that comes with DataMiner SRM, an operator who wants to instantiate a new service can then pick the right service definition, select the required resources and profiles, and set the time schedule. Only the resources that match the selected service type will be available for selection, and only if they have the capability and sufficient capacity to run the requested profiles, preventing any possible operational errors. Moreover, if the default Booking Manager app does not perfectly match your needs, you can create a custom booking wizard tailored to your specific workflows (e.g. simplified to the essentials).
Service definitions can be extended with DTR (Data Transfer Rules) scripts, which define a rule set for automatic resource selection and profile parameter inheritance during service setup. For example, if an HD input signal is selected for transport across an IP network, then the source encoder can automatically select HD-capable encoder and decoder edge gateways. This way, operators save even more time during service setup, and they also avoid inconsistencies in the configuration.
Automate every phase in your services' life cycles
Each service definition can be extended with a custom Life cycle Service Orchestration (LSO) script. This script can specify any life cycle state that the service should have, such as "paused", "standby", "switched to backup", etc. It also defines the transitions that need to happen between these states, which typically consist of a set of profile loads on the resources in the service.
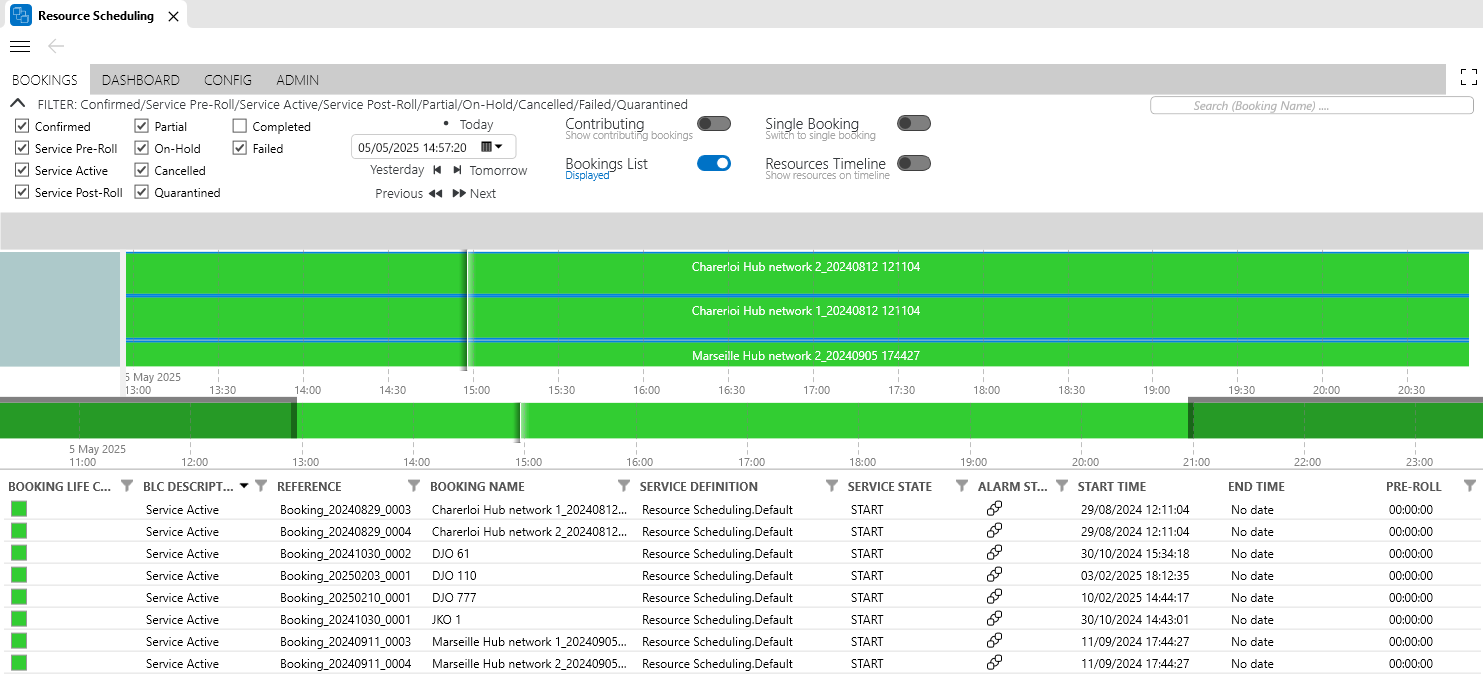
Booking states example in DataMiner Cube 10.5.5
Enhance visibility on your service quality and SLAs
To monitor your services, you can build visual overviews and dashboards that can be customized for every service definition individually. These monitoring views typically contain an east-west view and/or a north-south view of the service. An east-west view shows an end-to-end view of the entire service delivery chain and the status of all its components, while a north-south view shows a "vertical" slice of the technology stack on which the service is running, all the way down to the physical layer. This way, DevOps engineers can conveniently and consistently customize the look and feel of services.
By controlling service schedules, DataMiner can also enhance all its monitoring capabilities with service awareness. This can be used to for example adapt alarm templates of inventory based on the service it is included in, automatically start and stop SLA tracking based on a the state of a service (started/paused/stopped), or dynamically spin up QoS monitoring probes as part of certain life cycle transitions.
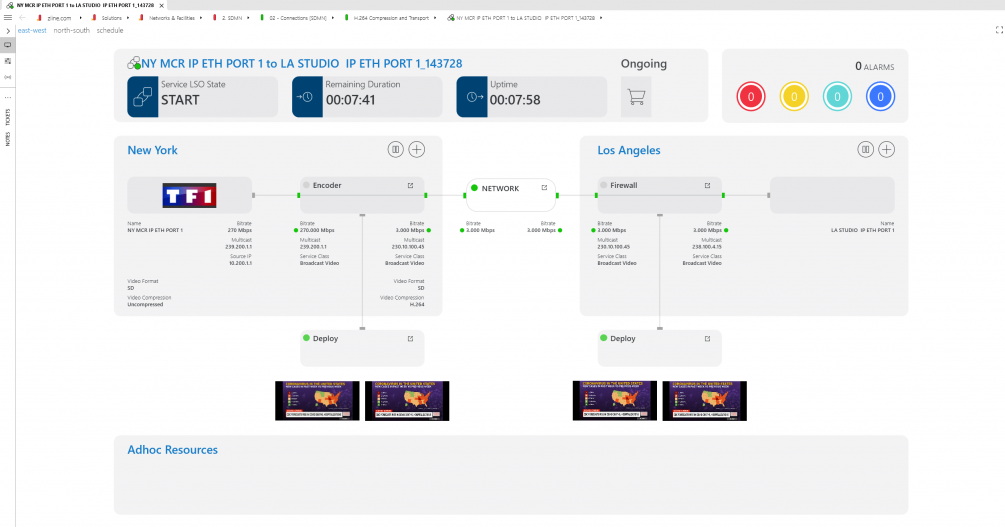
Service visual overview example